字符串——unicode 字符串 | 第二部分 类型与操作 —— 第 4 章: 介绍 python 对象类型 |《学习 python:强大的面向对象编程(第 5 版)》| python 技术论坛-江南app体育官方入口
python的字符串还带有在国际化字符集中处理文本所需的完整unicode支持。比如,日语和俄语的字母表中的字符就在ascii集之外。这些非ascii文本可以显示在网页,电子邮件,图形用户界面,json,xml或其他地方。当它出现时,处理好它就需要unicode支持。python内置了这些支持,但不同python产品线的unicode支持的形式也不同,并且这是他们最明显的差异之一。
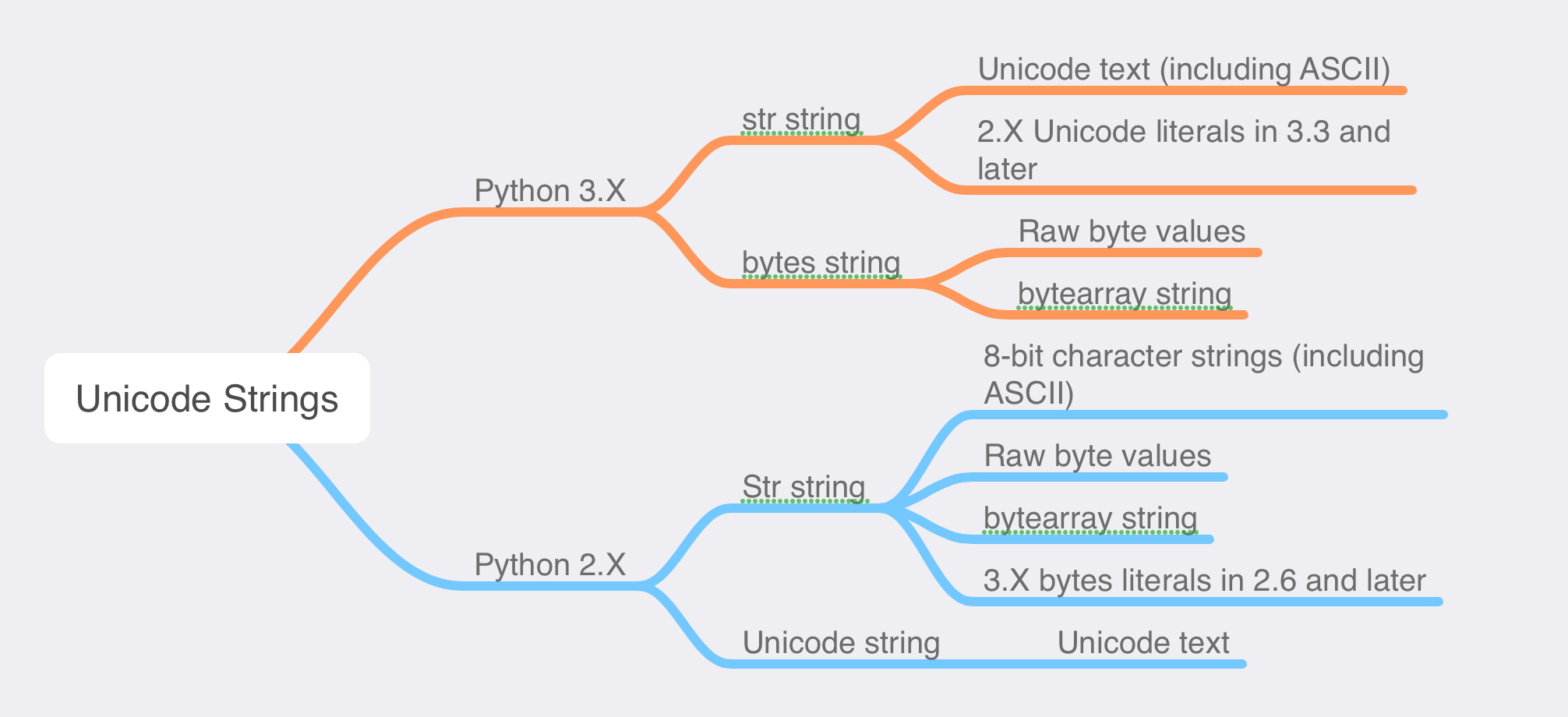
在python 3.x中,普通的 str 字符串处理unicode文本(包括ascii,它只是一种简单的unicode);明显不同的 bytes 字符串类型表示原始字节值(包括媒体和编码过的文本);并且为了兼容2.x,2.x的unicode字面量在3.3和之后版本中被支持(它们和普通的3.x str 字符串处理方式相同):
>>> 'sp\xc4m' # 3.x: 普通 `str` 字符串是unicode 文本
'späm'
>>> b'a\x01c' # 字节字符串是基于字节的数据
b'a\x01c'
>>> u'sp\u00c4m' # 2.x unicode 字面量适用于3.3 :只是字符串
'späm'在python 2.x中,普通的 str 字符串处理8位字符串(包括ascii文本)和原始字节值;明显不同的 unicode 字符串类型表示unicode文本;并且为了兼容3.x,3.x的字节字面量在2.6和之后的版本中被支持(它们和普通2.x str 字符串处理方式相同):
>>> print u'sp\xc4m' # 2.x: unicode 字符串是一个不同的类型
späm
>>> 'a\x01c' # 普通的 `str` 字符串包含基于字节的文本/数据
'a\x01c'
>>> b'a\x01c' # 3.x 字节字面量在2.6 中可用:只是字符串
'a\x01c'规范的说,在2.x和3.x中,非unicode字符串都是8位字节的序列,在可能的情况下使用ascii字符打印,而unicode字符串是unicode 码点(字符的识别数字,当编码到文件或存储到内存中时不一定映射到单字节)的序列。事实上,字节的概念不适用于unicode:一些编码包括对一个字节太大的字符码点,而且在一些编码和内存存储方案下,甚至简单的7位ascii文本也不是每个字符串存储一个字节:
>>> 'spam' # 在内存中,字符可以为1,2或4个字节
'spam'
>>> 'spam'.encode('utf8') # 在文件中,以utf-8编码为4个字节
b'spam'
>>> 'spam'.encode('utf16') # 但在utf-16中编码为10个字节
b'\xff\xfes\x00p\x00a\x00m\x00'3.x 和 2.x 都支持我们之前见过的 bytearray 字符串类型,它本质上是一个bytes 字符串(在 2.x中是 str),支持列表对象的大多数就地可变更改操作。
3.x和2.x也都支持使用 \x 十六进制和短 \u和长\uunicode转义,还有在程序源文件中声明的文件级编码。下面是在3.x中非ascii字符编码的三种方式(在2.x中添加一个前导“u”并说“print”效果相同):
>>> 'sp\xc4\u00c4\u000000c4m' # 3.x
'späääm'
>>> print u'sp\xc4\u00c4\u000000c4m' # 2.x
späääm这些值的含义和它们的使用方式在文本字符串(3.x中是普通字符串,而2.x中是unicode)和字节字符串(3.x中是字节,而2.x中是普通字符串)之间是不同的。所有这些转义都能被用来嵌套真正的unicode码点序列值整数到文本字符串中。作为对比,字节字符串只使用 \x十六进制转义来嵌套文本的编码形式,而不是它的解码的码点值——只有对某些编码和字符,编码字节和码点是相同的:
>>> '\u00a3', '\u00a3'.encode('latin1'), b'\xa3'.decode('latin1')
('£', b'\xa3', '£')作为一个显著的区别,只要普通字符串中的字符全是ascii,python 2.x 允许它的普通字符串和unicode字符串在表达式中混合;作为对比,python 3.x有一个更严格的模型,它从不允许它的普通字符串和字节字符串未经明确的转换而混合:
u'x' b'y' # 在 2.x 中可行(其中 b 可选且被忽略)
u'x' 'y' # 在2.x 中可行: u'xy'
u'x' b'y' # 在 3.3 中出错(其中 u 可选且被忽略)
u'x' 'y' # 在 3.3 中可行: 'xy'
'x' b'y'.decode() # 如果解码字节为字符串:'str',则在3.x中可行
'x'.encode() b'y' # 如果编码字符串为字节,则在3.x中可行:b'xy'除了这些字符串类型,unicode处理主要集中在文件中来回传输文本数据——当存储到文件时,文本是被编码为字节,当读取回内存时是被解码为字符(也就是码点)。一旦文本被加载到内存中,通常只将它作为解码形式的字符串来处理。
但是,由于这个模型,在3.x中文件也是特定于内容的:文本文件实现指定名称的编码和接收和返回 str 字符串,但二进制文件对于原始二进制数据用 bytes 字符串来处理。在python 2.x中,普通文件的内容是 str 字节,一个特殊的 codecs 模块处理unicode和使用 unicode 类型表示内容。
在本章稍后将再次见到文件中的unicode,但将unicode故事的剩余部分留在本书后面。它在第25章的一个与货币符号相关的例子中简短地出现,但大部分内容被推迟到本书的高级主题部分。unicode在一些领域十分重要,但许多程序员只是有基本的了解也能勉强应付过去。如果数据全是ascii文本,字符串和文件的主题在2.x和3.x中基本都是相同的。并且如果是编程新手,可以安全地推迟大多数unicode细节直到已经精通了字符串基础。
本节思维导图