『sd』如何控制人物姿态? | learnku 产品论坛-江南app体育官方入口
点赞 关注 收藏 = 学会了
在网上看到一张poss摆得不错的照片,想参考这个poss用 stable diffusion 生成一张图片,有什么办法?用精准的词语去描述这个动作?这么做太复杂了。
stable diffusion 的神级插件 controlnet 就提供了姿态控制这个功能。我们可以将参考图上传到 controlnet,让它推理出这个图片里人物的动作,然后再根据这个动作去生成另一张图片。
举个例子,前段时间很火的「塞尔达传说王国之泪」里面有一个人气角色叫「普尔亚」,我想按照下面这张图片人物的动作生成一个「普尔亚」的图片。

先看看最终效果。

开始动手实现。
第一步,将该图传到 controlnet 里。
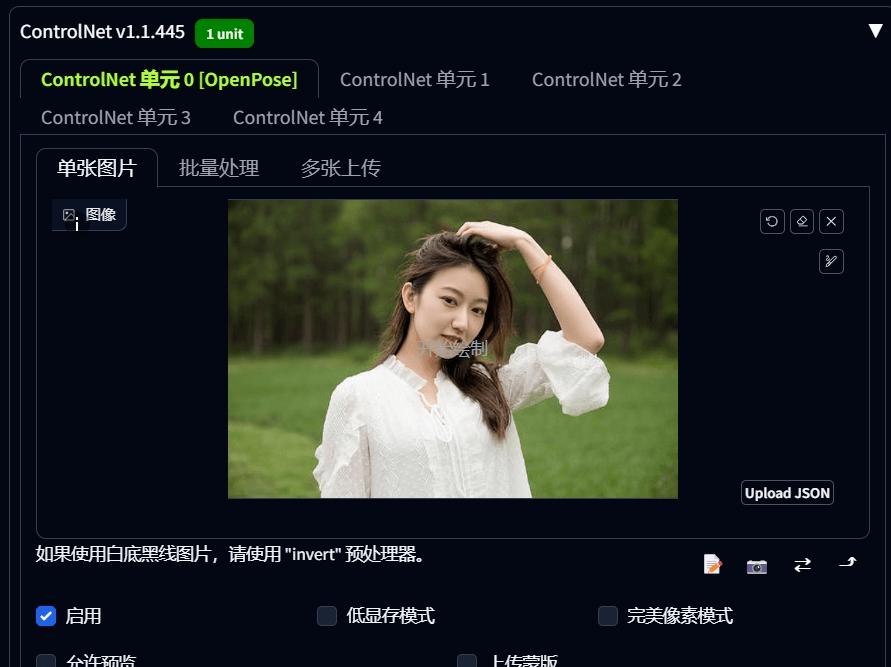
控制类型选择「openpose姿态」,然后点击一下 💥 按钮。
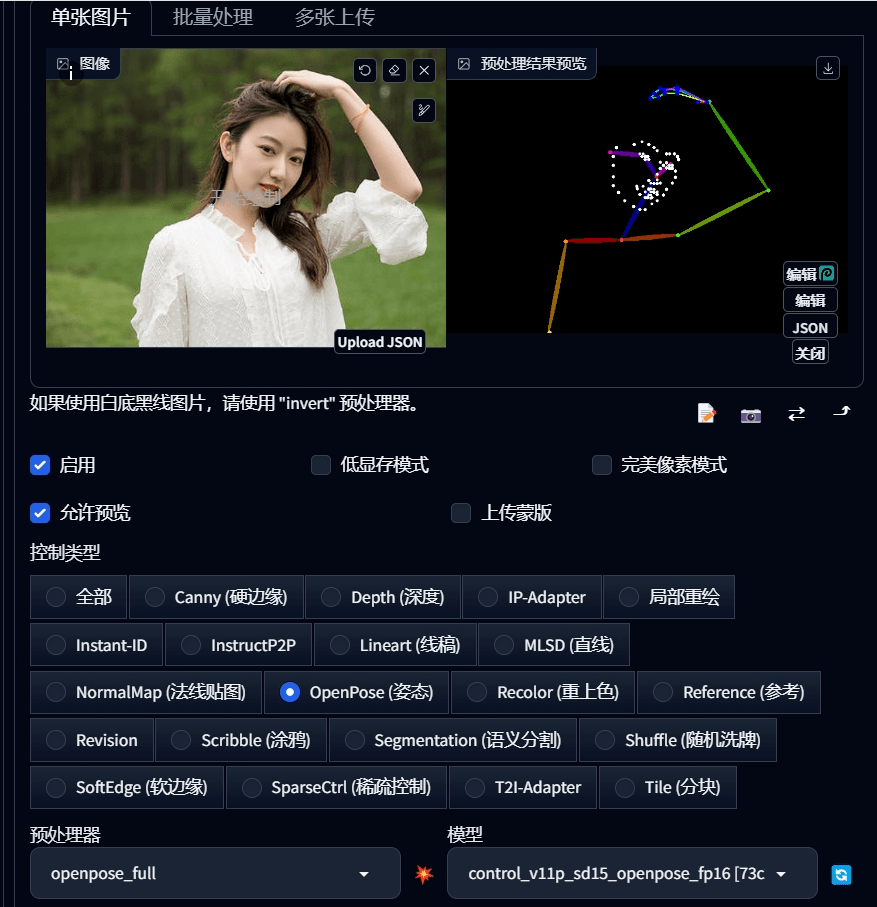
可以清楚看到,controlnet 已经把照片里的人物姿态识别出来了。
接下来的步骤就很简单了,在 controlnet 重选择 control_v11p_sd15_openpose_fp16 模型,该模型的下载地址:
如果你使用的是秋葉的资源整合包是自带了这些模型的。如果清楚怎么安装秋葉的资源整合包的工友可以看我之前写的 。
最后填入对应的提示词,选择「普尔亚」的 lora ,点击生成就能做出一张图片。
本例咒语:score_9,score_8_up,source_anime,1girl,solo,purah,hair ornament,red headband,red glasses,sleeveless shirt,white coat,black skirt,red leggings,gloves,looking at viewer,smile,cowboy shot,large breasts,happy,garden,blue sky,clouds,arms at sides,1">lora1,
negative prompt: 3d,photorealistic,monochrome,
steps: 28, sampler: euler a, schedule type: automatic, cfg scale: 7, seed: 2345096218, size: 528x352, model hash: 07341fcad2, model: aniverse_v30pruned, denoising strength: 0.5, rng: cpu, controlnet 0: “module: openpose_full, model: control_v11p_sd15_openpose_fp16 [73c2b67d], weight: 1, resize mode: crop and resize, low vram: false, processor res: 512, threshold a: 0.5, threshold b: 0.5, guidance start: 0, guidance end: 1, pixel perfect: false, control mode: balanced, hr option: both, save detected map: true”, hires upscale: 1.5, hires steps: 10, hires upscaler: 4x-animesharp, lora hashes: “purah-nvwls-v3-2: eaff243eb15b”, downcast alphas_cumprod: true, version: v1.9.4
本例用到的 lora 下载地址:
点赞 关注 收藏 = 学会了
本作品采用《cc 协议》,转载必须注明作者和本文链接
